Classification with Multimodal Learning
[Paper] [GitHub]
Gaurav Verma, Rohit Mujumdar, Zijie J. Wang, Munmun De Choudhury, and Srijan Kumar
Georgia Institute of Technology
⭐ Code and human-translated evaluation set released [GitHub link]
⭐ Released a summary video of the work [YouTube link]
⭐ Paper accepted at AAAI ICWSM 2022 [paper pdf]

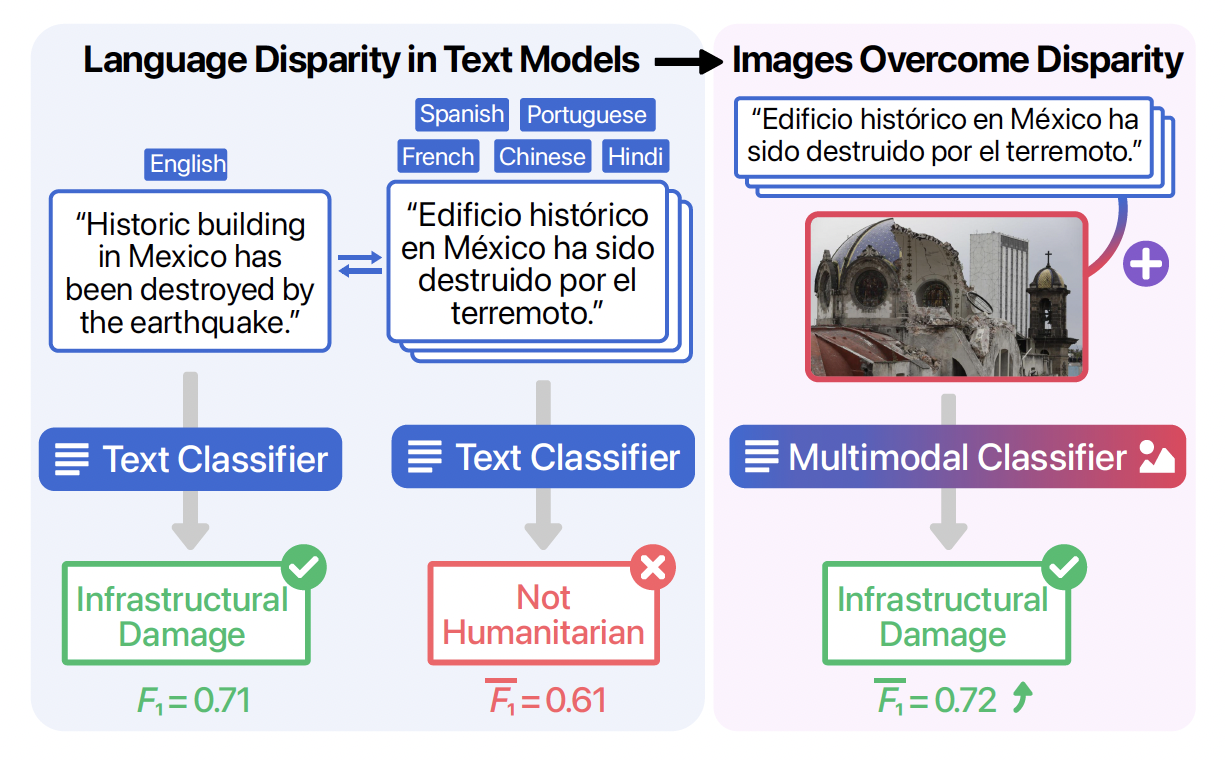 An example of a social media post that is correctly classified in English but misclassified in Spanish. Including the corresponding image leads to correct classification in Spanish as well as other non-English languages. F1 scores on all examples are also shown (average F1 score for all non-English languages.) |
|
Web data gives us a peek into people's lives – their ideologies, mental health indicators, and global events. About We ask: does the adoption of large language models (monolingual as well as multi-lingual) lead to disparity in performance across different languages while solving social computing tasks? We find, via experiments on 5 high-resource non-English languages and 3 social computing tasks, that both monolingual and multilingual models perform worse non non-English languages than on the English language. This means that detection technologies built around LLMs could lead to inequitable outcomes in crucial scenarios like detecting misinformation on social media (worse performance on Spanish posts than on English) or directing humanitarian interventions in times of crises. As a solution, we propose that using images – a modality that transcends language barriers, along with language could lead to lesser disparity between the performance on non-English and English models. The benefits of multimodal learning could complement the performance gains from developing better monolingual and multilingual models for non-English languages. Please read the paper for more details: pdf. |
Summary Talk (~5 mins)
| Advances in Natural Language Processing (NLP) have revolutionized the way researchers and practitioners address crucial societal problems. Large language models are now the standard for developing state-of-the-art solutions for text detection and classification tasks. However, the development of advanced computational techniques and resources is disproportionately focused on the English language, sidelining a majority of the languages spoken globally. While existing research has developed better multilingual and monolingual language models to bridge this language disparity between English and non-English languages, we explore the promise of incorporating the information contained in images via multimodal machine learning. Our comparative analyses on three detection tasks focusing on crisis information, fake news, and emotion recognition, as well as five high-resource non- English languages, demonstrate that: (a) detection frameworks based on pre-trained large language models like BERT and multilingual-BERT systematically perform better on the English language compared against non-English languages, and (b) including images via multimodal learning bridges this performance gap. We situate our findings with respect to existing work on the pitfalls of large language models, and discuss their theoretical and practical implications. |
Code, Dataset, and Human-Translated Evaluation Set
|
Code: We make the code for fine-tuning BERT-based monolingual and multilingual classifiers available. We have code available for the following languages: English, Spanish, Portuguese, French, Chinese, and Hindi. We also release the code to fine-tune a VGG-16 image classifier and the code for training a fusion-based multimodal classifiers. Datasets: In this work, we consider three social computing tasks that have existing multimodal datasets available. Please download the datasets from respective webpages: 1. Crisis humanitarianism (CrisisMMD): https://crisisnlp.qcri.org/crisismmd 2. Fake news detection: https://github.com/shiivangii/SpotFakePlus 3. Emotion classification: https://github.com/emoclassifier/emoclassifier.github.io (if you cannot access the dataset at its original source (proposed in this paper), please contact us for the Reddit URLs we used for our work.) Human-translated evaluation set: As part of our evaluation, we create a human-translated subset of the CrisisMMD dataset. The human-translated subset contains about 200 multimodal examples in English, each translated to Spanish, Portuguese, French, Chinese, and Hindi (a total of 1200 translations). We release this human-translated subset for aid evaluation in future studies. |
 |
Gaurav Verma, Rohit Mujumdar, Zijie J. Wang, Munmun De Choudhury, Srijan Kumar Overcoming Language Disparity in Online Content Classification with Multimodal Learning In Proceedings of the 16th International AAAI Conference on Web and Social Media (ICWSM), 2022. webpage: https://multimodality-language-disparity.github.io/ arXiv: https://arxiv.org/abs/2205.09744 |
Bibtex:
|
|
|